Personal Value Ratings for Presidential Speeches
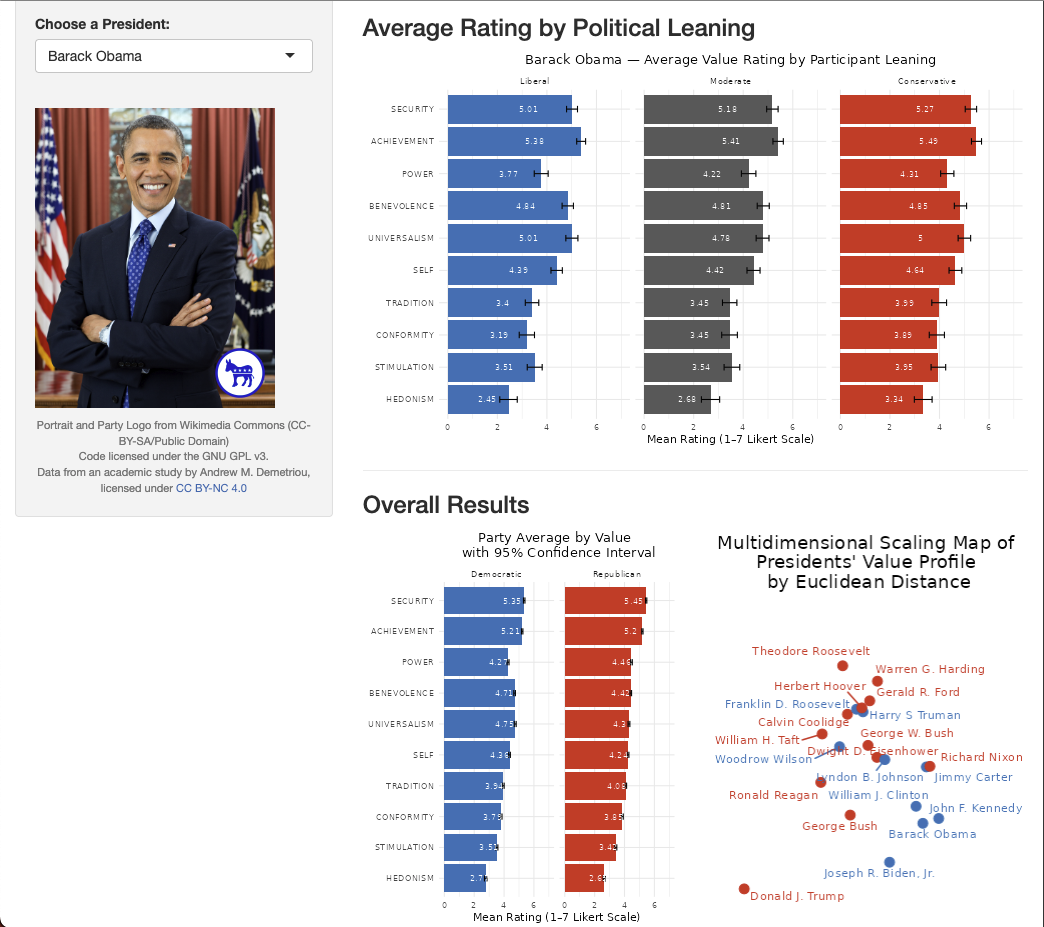
Presidential speeches provide a rich context for examining how differently values are perceived when it comes to political communication. In this work, we ‘ground’ personal values in excerpts from US Presidential State of the Union addresses, using theory from the Social Sciences. Participants from a US sample rated speech excerpts on ten Schwartz values. We then examined how differently participants rated the values of the speech, based on their own political leanings. The dashboard shows average ratings by party, as well as a multidimensional scaling map that places presidents in a two-dimensional space based on similarities in their value profiles. Together, these views allow exploration of differences in ratings across presidents.
Towards Automatic Personal Value Estimation in Song Lyrics with Large Language Models
ISMIR, 2025 (under review) · Supplement ·
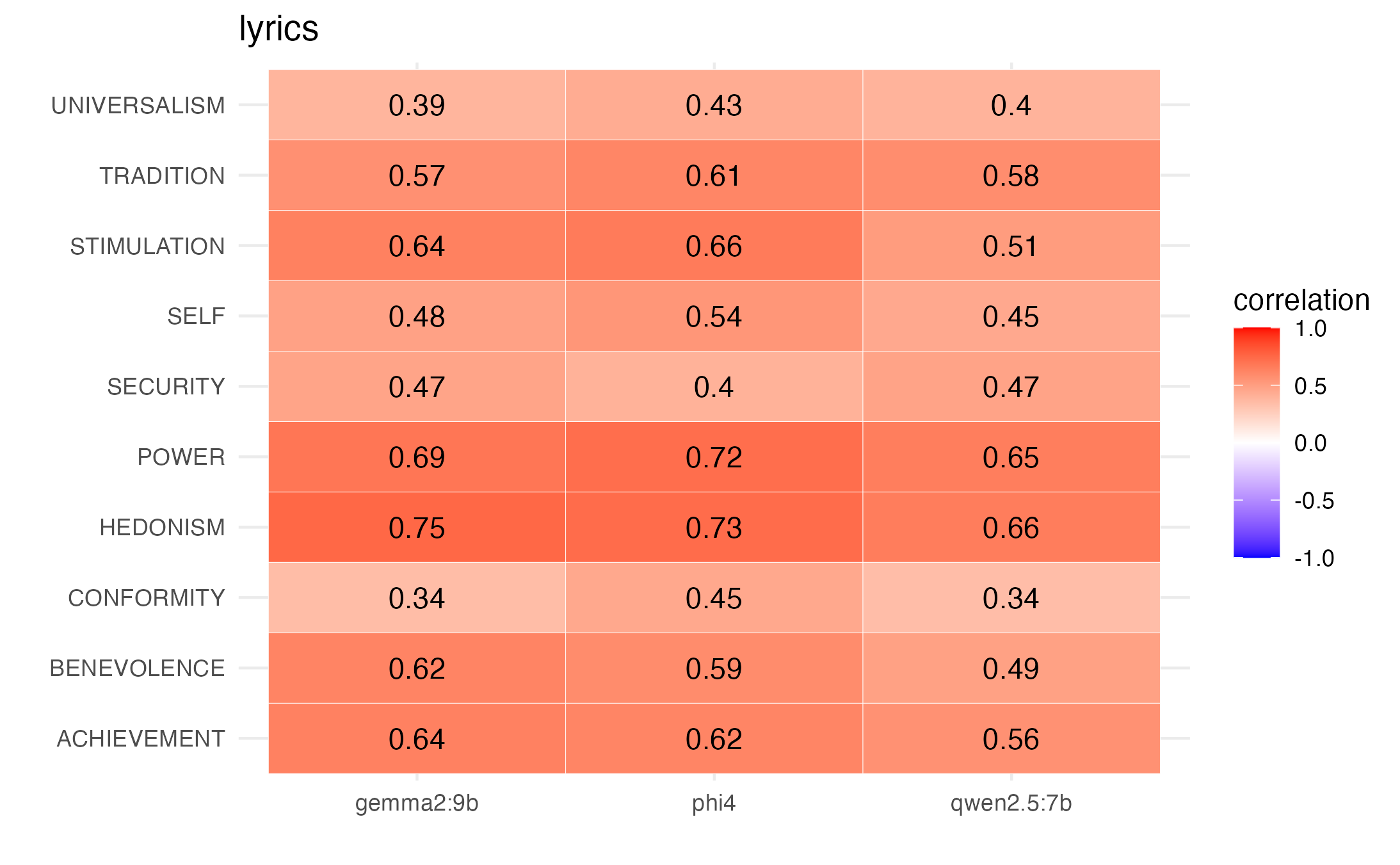
Popular Western music almost always includes lyrics. In this work, we ‘ground’ personal values in lyrics, using theory from the Social Sciences. We then evaluate a group of language models on how well they estimate values in the lyrics. Figure shows pearson correlations between mean ratings of participants from a US sample stratified by ethnicity with mean ratings of 3 runs per model (gemma2:9b, phi4,qwen2.5:7b), by value. We show small to moderate positive correlations overall.
Position: Stop Making Unscientific AGI Performance Claims
Developments in AI and related fields, particularly large language models (LLMs), have created a ‘perfect storm’ for observing ‘sparks’ of Artificial General Intelligence (AGI) that are spurious. We argue and show that finding of meaningful patterns in the latent spaces of these models isn’t evidence of AGI. Figure shows model outputs in response to sentences about inflation and deflation of prices (IP and DP), and inflation and deflation of birds (IB and DB). The vertical axis shows predicted inflation levels subtracted by the average predicted value of the probe for random noise. If the model had ‘understood’, we would expect a significant difference in the predictions - instead we find the outputs are similar. We review literature from the social sciences on anthropomorphization, and how both the methods and public image of AI are ideal for the misinterpretation of output as ‘understanding’. We call for more caution in the interpretations of research results from the academic community.

Annotation Practices in Societally Impactful Machine Learning Applications: What are Popular Recommender Systems Models Actually Trained On?
Workshop: Perspectives on the Evaluation of Recommender Systems, 2023
Alexandria: A proof-of-concept micropublication platform
Website · Open Science Framework ·
Alexandria is a design for a collaborative open-source platform for publishing, discussing, and developing scientific research. It was designed in conversation with Cynthia Liem’s lab at TU Delft, and two software bachelor student groups, and one masters UX design student. The aim was to combine version control (git) with an intuitive, community-driven interface inspired by wikipedia. Users can share reflections, ask questions, or publish work.
The definition of ‘work’ is broad, and includes data, code, or any other relevant material. Everything remains editable, and can be copied and changed by the community: inspired by Wikipedia, it encourages micro-publication, and collaboration on shared materials similar to articles - but with a focus on the narrow topics and additional materials needed for science. Changes are proposed and reviewed by peers with relevant expertise - although formally defining this process would require further study. Posts themselves are Quarto repositories rendered into readable html pages, bridging the gap between code and final research outputs.

Psychology Meets Machine Learning: Interdisciplinary Perspectives on Algorithmic Job Candidate Screening
Book: Explainable and Interpretable Models in Computer Vision and Machine Learning, 2018